从随机生成到工业级可控的范式转移
AI绘画正从“随机生成”转向“工业级可控”。到2026年3月,这项技术已不再是设计师的辅助插件,而是直接嵌入商业工作流的底层环节。其本质是通过大规模数据集训练,实现从自然语言到像素空间的精准映射。
画师的竞争力正在发生结构性转移。过去,核心竞争力是对线条、色彩和构图的掌控;现在,则演变为对视觉语言的解构能力与模型参数的调优能力。这种转变导致生产力层级出现断层:在UpWork和Fiverr等平台,基础原画和低端插画的单价在2024年后剧降,主因是AI将原需三天的工时压缩至三分钟,导致大量初级画师失去生存空间。
核心原理:理解扩散模型的去噪逻辑
要掌握AI绘画,必须理解扩散模型(Diffusion Models)的逻辑
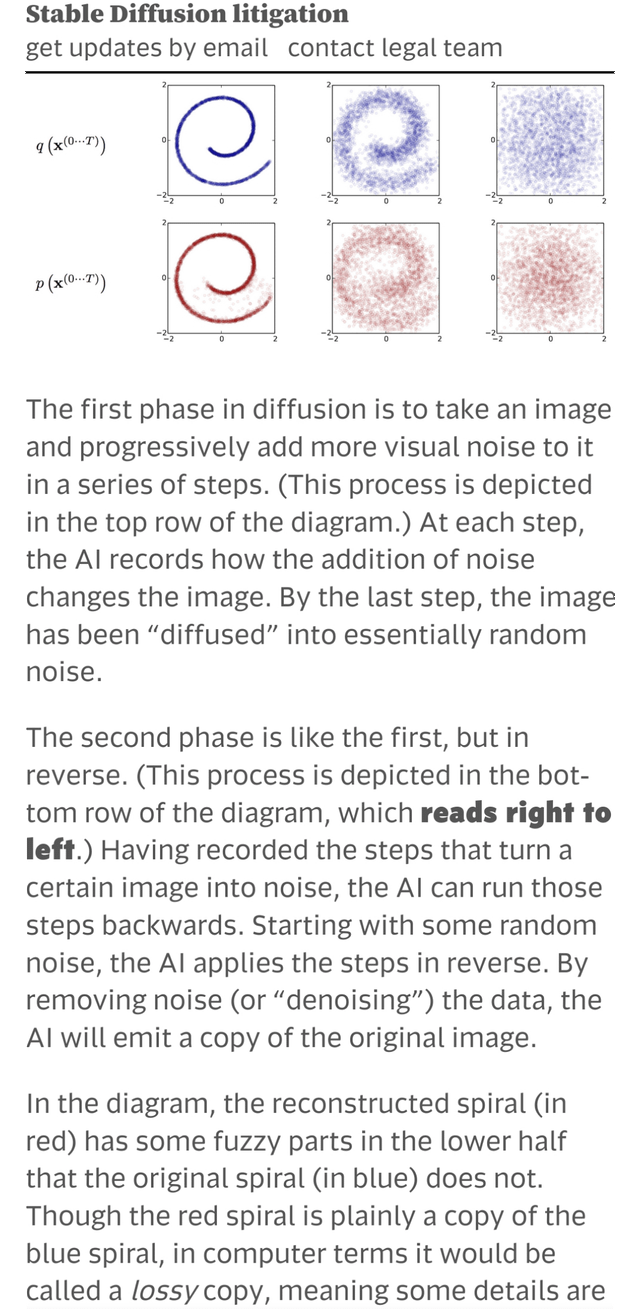
模型先将图像通过高斯噪声变为随机状态,再训练神经网络预测并剔除噪声以还原图像。当你输入“赛博朋克东京街道”,模型是在概率空间中寻找相关像素分布并将其具象化。因此,单纯依赖提示词(Prompt)“抽卡”无法保证商业稳定性。
工业级 AI 绘画商业化实操路径
针对2026年的从业者,建议构建“模型训练 $\rightarrow$ 精准控制 $\rightarrow$ 后期修正”的闭环路径。以下是基于Stable Diffusion 3.5等工业级工具的实操指南:
1. 构建专属 LoRA 模型确保视觉统一
首先,通过构建专属LoRA模型确保视觉统一

1. 准备15-30张高质量、风格统一且背景简洁的参考图。
2. 使用 Kohya_ss 工具,设置学习率 1e-4,迭代次数约 2000 次。
3. 进行精准打标签(Captioning),将角色特征与环境元素剥离。
4. 加载模型并使用触发词,若出现过拟合(噪点/僵硬),降低权重或减少轮数。
2. 利用 ControlNet 掌控构图
其次,利用ControlNet掌控构图

在WebUI或ComfyUI中上传线稿或OpenPose人体姿势图,选择Canny边缘检测或Depth深度图模型,将权重设为0.7-0.9。AI将被锁定在指定线稿内,而非随机猜测。若出现线条丢失,可将“控制步数”设为0.6,使AI在前60%阶段遵循线稿,后40%阶段进行细节润色,兼顾艺术感与透视精度。
3. 局部重绘与超分辨率交付
最后,通过分层局部重绘(Inpainting)与超分辨率放大完成商业交付

1. 使用遮罩(Mask)涂抹畸形手指或错误阴影。
2. 将“重绘幅度”(Denoising Strength)控制在 0.4-0.6 之间进行修正。
3. 使用 Tile 扩散算法提升至 4K/8K 分辨率。
4. 开启 Face-Restore 模型防止面部崩坏。
主流 AI 绘画方案对比分析
主流方案的适用场景存在明显差异

| 方案 | 核心优势 | 主要劣势 | 适用场景 |
|---|---|---|---|
| Midjourney | 审美极高,出图快 | 黑盒操作,难以精准修改 | 创意启发、概念图 |
| Stable Diffusion | 开源生态,工业级控制 | 学习曲线陡峭,依赖 GPU | 商业生产、精准定制 |
| Adobe Firefly | 版权合规,集成度高 | 艺术上限相对较低 | 快速修图、企业合规项目 |
AI 绘画是否存在无法逾越的边界?
是的。AI 难以处理强时序性和物理因果关系(如复杂的肢体交互与物体掉落逻辑),在毫米级精度的工业设计图中仅能提供参考,且缺乏真正的“意图”与深层情感理解。
画师在 AI 时代应如何构建竞争力?
应将工作流由单一创作转变为“审美 + 调度能力”。建议采用“AI打底 $\rightarrow$ 手绘精修 $\rightarrow$ AI升采样”的链路,并致力于构建私有视觉资产库。
总结与前瞻
与其纠结是否被替代,不如提升“审美 + 调度能力”。现在可以尝试搭建ComfyUI工作流,将重复性渲染交给机器,把思考时间留给创意。